
Excelを使うオフィスワーカーであれば
- 販売データに顧客マスタの年代や住所・年収などの情報を追加する
- 顧客データに営業データを照合して営業済かどうか判定する
など、VLOOKUPには大変お世話になってますよね。
便利である反面、データ数が多くなると「重くて時間がかかる」「フリーズする」「Excelが強制終了する」などのトラブルは、誰しも一度は経験したことあるのではないでしょうか。
こんなときは、検索方法「TRUE」を使うことでVLOOKUPを爆速化して解決できちゃいます♪
30万行の販売データに80万行の顧客マスタをVLOOKUPするケースだと、なんと2万倍近くの高速化が実現可能…!!
結論は次の通りです。
【STEP①】検索範囲側(マスタ側)の検索値を昇順にソート
【STEP②】検索値(キー情報)をTRUEで突合
【STEP③】TRUEで取得した情報とキー情報の一致を確認して、IF文で制御
記事内では「そもそもなんでFALSEだと重いのか」「TRUEだと早くなるのか」について、アルゴリズムの観点からも補足してます。詳細を知りたい方はぜひ本文をご参照ください!
おさらい!VLOOKUPで出来ることと基本的な使い方
VLOOKUPで出来ることは他データ群にある情報を取得・付加すること
VLOOKUPでは、特定の検索値について、マスタなど検索範囲側の情報を取得・付加することができます。
例えば販売履歴のデータに対して、顧客マスタの情報を追加するなどがあげられます。
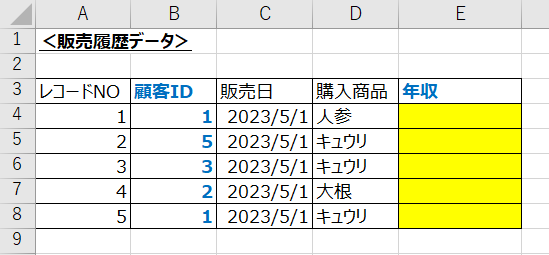
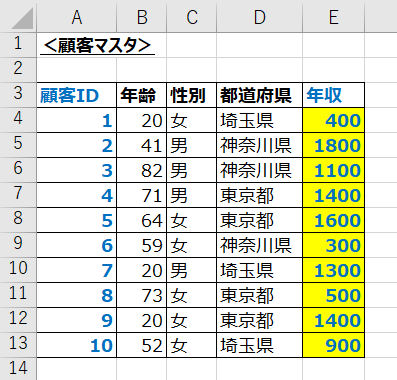
VLOOKUPの基本的な使い方
VLOOKUPは、(検索値,検索範囲,列番号,検索方法) を指定することが使うことができます。
検索値は検索範囲を検索するための値、列番号は検索値から右に何列目の情報か、検索方法はとにかくFALSEを指定とならいましたね。
先ほどの例では販売データに年収情報を追加したいため、検索値が「顧客ID」、検索範囲が「顧客マスタ」、列番号が「5」、検索方法は「FALSE」となります。
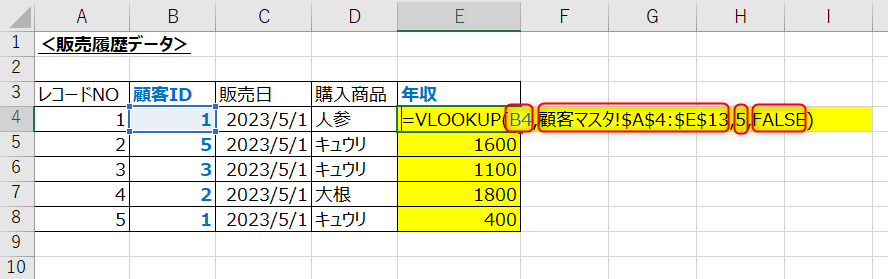
↓
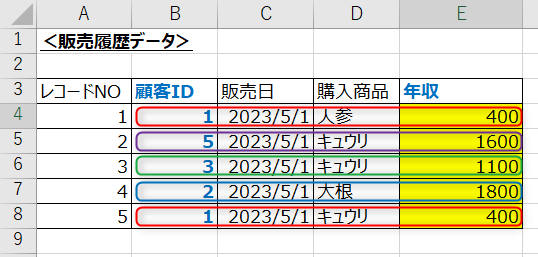
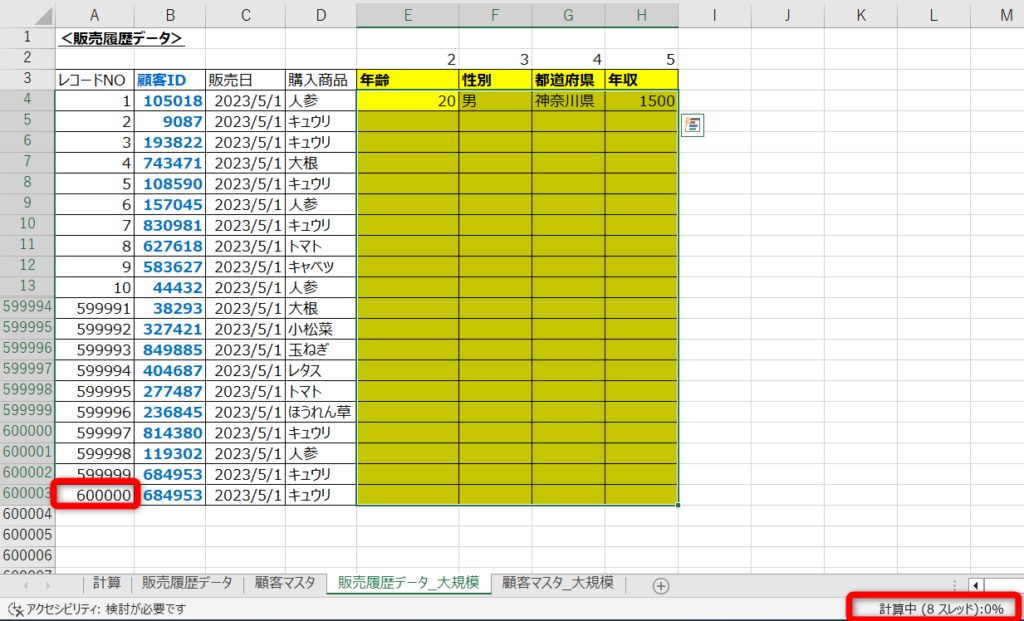
この方法はデータの取り扱い上ミスも少なく一番安全な方法です。
ただ欠点としてデータ量が大きいと計算負荷が高く、時間がかかったり、そもそも計算できなくなったりします。
VLOOKUPを高速化する検索方法「TRUE」の指定
前章ではデータ量が大きくなると、VLOOKUPが重くなる課題について触れました。
この課題を解消するための手段が、検索方法に「TRUE」を使うこと。
理由は次の章で紹介しますが、驚くほど爆速化します。ここではまずは使い方についてご紹介します。
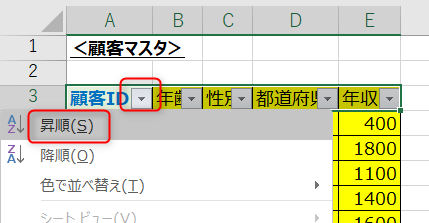
STEP①検索範囲側(マスタ側)の検索値を昇順にソート
まずは下準備として、検索範囲側(マスタ側)の検索値を昇順にソートします。
昇順にするのはTRUEの検索結果を導くアルゴリズムが正しく判定出来るようにするためです。詳しくは後述します。
今回は販売履歴データの顧客IDに対して、顧客マスタの年収を紐づけたいので、顧客マスタ側の顧客IDを昇順にソートします。
ソートはエクセルのフィルター機能を活用すると良いでしょう。※エクセルのソートが文字列の場合、必ずしも正しくない可能性もあるらしく、別途調査します。
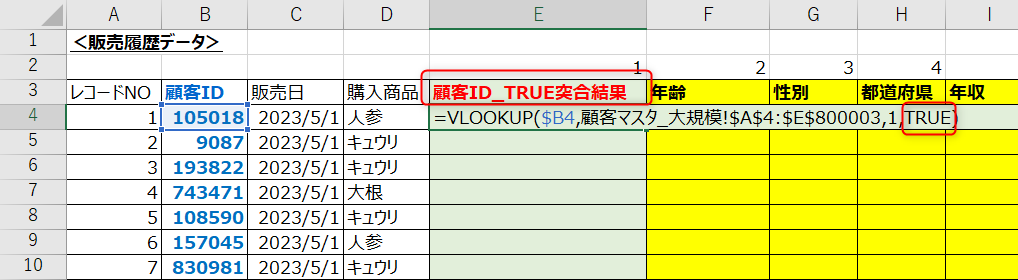
STEP②検索値(キー情報)をTRUEで突合
続いて、検索値(キー情報)をTRUEで突合します。
使い方は通常のVLOOKUPと全く同じで、FALSE指定していたところをTRUEで指定するだけ。
STEP③TRUEで取得した情報とキー情報の一致を確認して、IF文で制御
「TRUE」での検索結果は「FALSE」での検索結果と異なり、完全一致検索ではなく、近似値検索となります。
つまり、マスタ側に検索データが存在しない場合、「FALSE」では一致データがないためN/Aとなりますが、「TRUE」の場合は近い値を紐づけてしまいます。
例えば、販売履歴データでは830981という新規顧客が出てきたものの、顧客マスタは更新が間に合っておらず1~800000までしかないケースだと、「FALSE」ではN/Aを返しますが、「TRUE」だと800000を返します。(以下図参照)
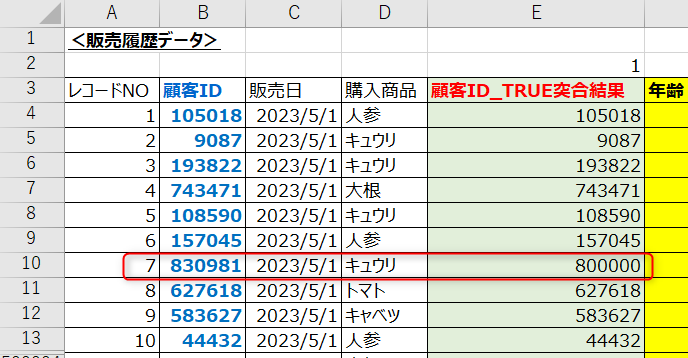
そこで誤った紐づけを回避するよう、一工夫しておく必要があります。
オススメなのはIF文を使った制御。元の検索値とTRUEで紐づけた結果が同じかを判定し、同じであれば取得したい列番号を記載したVLOOKUPを、同じでなければN/Aを指定すれば、FALSEと同じ挙動になります。

↓
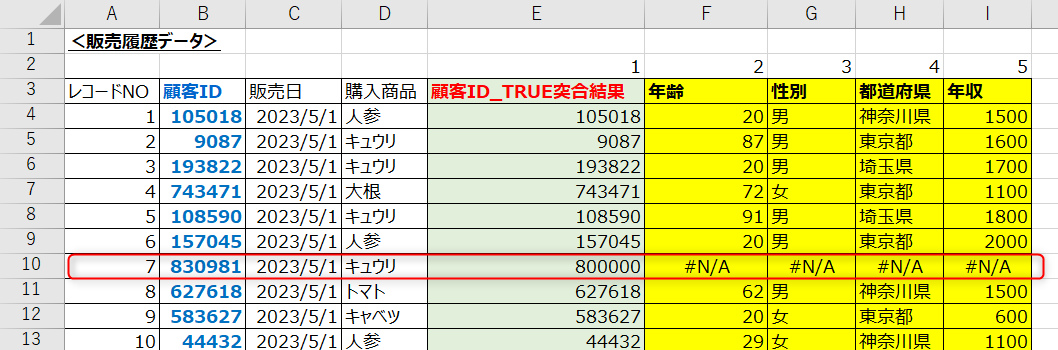
一工夫必要なのでなんでもかんでも「TRUE」が良い訳ではありませんが、10万行を超えるなどある程度データ量が多くなってくると圧倒的に早くなるため、ぜひ「TRUE」を活用ください。
なぜ「TRUE」だと早くなるのか?アルゴリズムから読み解く
ここではなぜ「TRUE」だと早くなるかの詳細について解説します。知らなくても問題はないので、読み飛ばしてもOKです。
FALSEは線形探索
FALSEの検索アルゴリズムは線形探索と呼ばれるアプローチで、端的に表すと検索範囲のデータを上から順番に探していきます。
検索値が上の方、例えば10行目くらいであれば10回の検索で見つかるものの、60万行目など下の方ににいると60万回の検索が必要になるため、中々ハードな検索スタイルです。
平均するとデータ個数の半分程度の検索回数が必要です。
検索範囲が数百~数千行程度なら問題ですが、10万行規模になると、1回のVLOOKUPで5万回の検索が必要となるため、マスタ側のデータが多いと重くなりがちです。
メリット:使い方が簡単でミスしにくい、昇順ソートなどの加工がいらない
デメリット:データ量が大きいと遅い、実質使えない
TRUEは二分探索(バイナリサーチ)
TRUEの検索アルゴリズムは二分探索(バイナリサーチ)と呼ばれるアプローチです。
検索範囲の真ん中をみて検索したい値より大きいか小さいかを判定し、小さければ最初から真ん中までのさらに真ん中、大きければ真ん中から最後までのさらに真ん中を検索するという探索を繰り返します。
分かりづらいと思うので、1~15のデータから10を探索する事例を以下に載せます。この例だと10を検索するにに3回の探索で終了していることがわかります。(線形探索だと10回の探索が必要)

この手法の肝は1回の検索で検索の半分を終わらせることができること、つまり検索回数がnづつ線形で増えるのではなく、2^nと非線形にしか増えないことです。
具体的には80万行の検索でも、
2^19=524,288 < 80万 < 2^20=1,048,576
なので20回の探索で終わる超優れものです。
80万行の検索はFALSEの場合は平均40万回必要なので、なんと脅威の2万倍の検索スピード!これは早い、まさに爆速!
「TRUE」の使い方で最初に昇順にソートするとしていたのは、この二分探索のアルゴリズムの前提が、データが昇順になっていることなので、まずは昇順にソートする必要がありました。
メリット:圧倒的スピード!データ量の制約を実質受けない
デメリット:加工が必要、近似検索なので誤った値を紐づける可能性があるため一工夫が必要
まとめ:VLOOKUPが重くてつらいときは検索方法「TRUE」を活用しよう
本記事では検索方法「TURE」を活用した、VLOOKUPの高速化の方法について紹介しました。
【STEP①】検索範囲側(マスタ側)の検索値を昇順にソート
【STEP②】検索値(キー情報)をTRUEで突合
【STEP③】TRUEで取得した情報とキー情報の一致を確認して、IF文で制御
ちょっと加工が必要であるものの、大規模データを使う際は世界が変わるテクニックです。ぜひ覚えて活用してみてください♪








